Welcome to the forums at seaphages.org. Please feel free to ask any questions related to the SEA-PHAGES program. Any logged-in user may post new topics and reply to existing topics. If you'd like to see a new forum created, please contact us using our form or email us at info@seaphages.org.
Recent Activity
All posts created by dwilliams
| Link to this post | posted 19 Dec, 2023 19:13 | |
|---|---|

|
Hi Fred, This seems like it could go either way. The lack of coding potential and absence of being called in other genomes (a decent number of them) is compelling to be conservative. The operon overlaps are intriguing and I usually weigh them pretty heavy when making decisions. It does seem like there is something interesting going on with respect to DNA metabolism in this region of the P1 cluster. Without some more definitive support I'd leave it out. |
Posted in: Gene or not a Gene → Gene or no gene at Subcluster P1 phage Sonah position 37305-37388 bp?
| Link to this post | posted 23 Jun, 2023 18:15 | |
|---|---|
|
|
Thanks for the guidance. I've been exporting .ppt files as .png at 2000 px by 1175 px and that size seems reasonable when expanded on genesdb. Images of individual cytotoxic plates are 300 ppi and the overall file size is around 1.8 MB. It might be a bit larger than needed for accurate representation of data, but it hasn't crashed a server…. yet. |
Posted in: Data Upload Questions → Image file size
| Link to this post | posted 04 Jun, 2023 19:52 | |
|---|---|
|
|
Hi Debbie, something else. These are gel images datacards or cytotoxic assays for the GENES database. I don't want to have images submitted that are too small or be useful or too large to bog down servers or other users machines. |
Posted in: Data Upload Questions → Image file size
| Link to this post | posted 04 Jun, 2023 14:56 | |
|---|---|
|
|
Is there a recommended file size for images to be uploaded? |
Posted in: Data Upload Questions → Image file size
| Link to this post | posted 14 Oct, 2021 19:41 | |
|---|---|
|
|
Hi Amanda, I can't speak for everyone and have only briefly looked at the template, but this seems reasonable. If I were doing QC on PumpkinSpice, I would use your PECAAN Notes and verify it against the minimal file to make sure things are consistent. My hunch is that if you used PECAAN to annotate and keep student's work in one location, then used the PECAAN output to generate your DNAMaster complete notes and minimal file, then you should be good to go. |
Posted in: Notes and Final Files → Question about notes template
| Link to this post | posted 21 May, 2020 20:36 | |
|---|---|
|
|
I've got a similar result to Nurujay_Gp52 (41973). In this case I think there is strong evidence of being RNA polymerase sigma factor, specifically an extracytoplasmic sigma factor (ECF), of which are are large family of diverse alternative sigma factors that regulate genes in response to different environmental changes. Attached is the HHPRED alignment between Jorgensen_51 and sigmaL from M. tuberculosis. ECF sigma factors are smaller than other sigma factors, are are comprised of two conserved domains (R2 and R4) that are connected by an unstructured linker. The crystal structure (6DVC) is of RNA polymerase, sigmaL and DNA and demonstrates interaction between R2 of sigmaL and the -10 region of the non-template strand. In light of other discussion on sigma factors…. Is this a RNA polymerase ECF sigma factor (new function) or transcription factor (not on the list)?? Alternatively RNA polymerase sigma factor (on the list) seems reasonable. |
 493Kb
493KbPosted in: Annotation → Function for Gene 1 of EK1 Phages
| Link to this post | posted 24 May, 2019 15:08 | |
|---|---|
|
|
I'm annotating Gordonia phage Kenosha (DJ) and would like to call Kenosha_65 (Pham 46635) as ssDNA binding protein. BLAST at NCBI or PhagesDB isn't helpful because the hits do not have assigned functions. HHPRED returns a high probability hit with a recently crystalized ssDNA binding protein over ~75% of Kenosha_65 and most of the crystalized ssDNA binding protein (attached). The e values of HHPred are not good but the structure paper indicates structural similarity with T7 2.5 (a ssDNA binding protein), despite the low similarity at the sequence level. There is pretty good matches between query and subject in areas of the protein that have conserved single stranded DNA binding residues. Plus Kenosha 65 is 5 genes downstream of DNA primase/polymerase. Any thoughts from a higher authority? |
 133Kb
133KbPosted in: Functional Annotation → ssDNA binding protein
| Link to this post | posted 21 May, 2019 19:10 | |
|---|---|
|
|
I am incredibly interested in this post and would love to know the mechanism by which DNA modification can lead to instability of purified DNA under specific conditions. At the very least, it is an interesting puzzle to solve…. I saw this last year with some smeg phages. I forget the specific ones, but recall that I attributed the smearing to residual nuclease present that refolded in RE buffer based on smears present when RE buffer was added, but not no buffer added controls. This year with Gordonia phages and pre-treating them with PK and SDS, we had OK success with getting DNA. By OK I mean that there wasn't the smearing of extracted DNA, but addition of enzyme didn't result in production of a digested genome. Because I don't know whether the enzyme sites were present in the genomes analyzed, I don't know whether enzyme cleavage failed or not. I look in notebooks tomorrow and see if I can find anything. dw |
Posted in: Phage Biology → DNA Smear
| Link to this post | posted 09 May, 2019 19:53 | |
|---|---|
|
|
What is the function call for this? Some recent annotations (Duffington and Rickmore) are listed as "capsid & capsid maturation protease", but that is not on the function list. "major capsid and protease fusion protein" is on the list. |
Posted in: Cluster DJ Annotation Tips → capsid fusion
| Link to this post | posted 25 Feb, 2019 22:58 | |
|---|---|
|
|
We have two phages isolated using G. rubripertincta (Mayweather and Kenosha) that are currently being annotated. Some rather observant students in class noticed things about the GeneMark outputs and coding potential and have been hounding me for an answer. The first is a little "carrot" that is present near the start of one particular ORF (see the red box on the attached image). What does the little carrot signify? There second question is why there is a difference in the GeneMark output for Kenosha compared to Mayweather. I think I have an answer for them, but it brings up another question. Mayweather is 48K bp, while Kenosha is 60K bp. When GeneMarkS is run from phagesDB, the output is the Heuristic version of GeneMark, while Kenosha is the self-trained version. On the GeneMark site, it indicates GeneMarkS can be run on sequences longer than 50kb, so I assume that GeneMarkS on phagesDB reverts to the heuristic version on sequences less than 50kb? The bigger issue is that the heuristic output is pretty noisy and often there is not a clear plateau of coding potential. Because of this should the relative importance of CP be adjusted when determining starts? Is G. terrae a decent proxy for G. ruberipertincta on species trained GeneMark? Thanks dan |
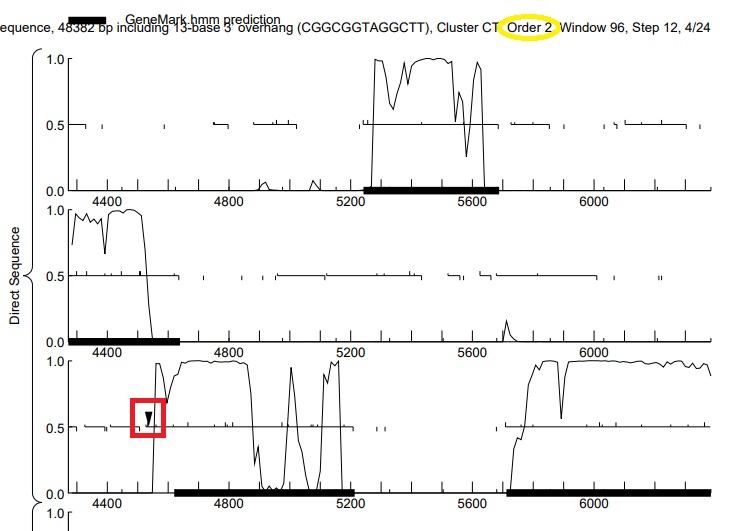 70Kb
70KbPosted in: Annotation → GeneMark and G rubripertincta