Welcome to the forums at seaphages.org. Please feel free to ask any questions related to the SEA-PHAGES program. Any logged-in user may post new topics and reply to existing topics. If you'd like to see a new forum created, please contact us using our form or email us at info@seaphages.org.
Recent Activity
GeneMark and G rubripertincta
| Link to this post | posted 25 Feb, 2019 22:58 | |
|---|---|

|
We have two phages isolated using G. rubripertincta (Mayweather and Kenosha) that are currently being annotated. Some rather observant students in class noticed things about the GeneMark outputs and coding potential and have been hounding me for an answer. The first is a little "carrot" that is present near the start of one particular ORF (see the red box on the attached image). What does the little carrot signify? There second question is why there is a difference in the GeneMark output for Kenosha compared to Mayweather. I think I have an answer for them, but it brings up another question. Mayweather is 48K bp, while Kenosha is 60K bp. When GeneMarkS is run from phagesDB, the output is the Heuristic version of GeneMark, while Kenosha is the self-trained version. On the GeneMark site, it indicates GeneMarkS can be run on sequences longer than 50kb, so I assume that GeneMarkS on phagesDB reverts to the heuristic version on sequences less than 50kb? The bigger issue is that the heuristic output is pretty noisy and often there is not a clear plateau of coding potential. Because of this should the relative importance of CP be adjusted when determining starts? Is G. terrae a decent proxy for G. ruberipertincta on species trained GeneMark? Thanks dan |
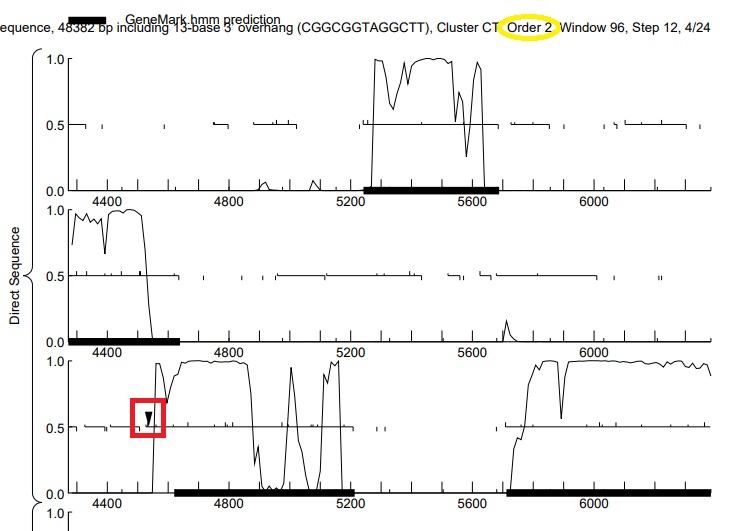 70Kb
70Kb| Link to this post | posted 19 Mar, 2020 21:47 | |
|---|---|
|
|
Good Afternoon DWilliams, The little carrot shows an area where the HMMs (Hidden Markov Models) predicts that a slip has been detected. If it isn't for the tail assembly chaperone, this can be ignored by the students. As for the second question… I've bumped into an incredibly similar issue and will be following this thread. Thank you! ~ D'Andrew |
| Link to this post | posted 20 Mar, 2020 01:20 | |
|---|---|

|
Hi Dan and D'Andrew, Interesting. I can tell you (as the person who programmed the button on PhagesDB) that the same exact request is sent to GeneMark in both the Mayweather and Kenosha cases. So it must be GeneMark itself that is making a decision about which model/method to use. From the PhagesDB perspective, we don't distinguish based on length or anything. –Dan |
| Link to this post | posted 21 Mar, 2020 20:06 | |
|---|---|

|
Hi all, I got curious about this, because technically I thought a heuristic model and one that is trained on self were the same thing. GenemarkS was written for 'bigger' genomes. I believe it is as suggested, that the decision as to what server a genome is sent to is its length. I picked a few genomes and ran GeneMarkS at phagesDB (with the buttons). It looks like smaller genomes, below 50k, are run through GeneMark's heuristic program and ones that are larger, greater than 50k, through the GeneMarkS program. (Check out the GeneMarkS output of PSullivan (49990 nt) and Pistachio (50006 nt). If you don't like the noise of the heuristic modeling, you can run GeneMark at their website using GeneMarkS. By the way, I have been working on a few papers with Graham, where repeat sequences are analyzed. These analyses have shown that 'capturing all coding potential' is not always the best answer. Happy annotating! |
 209Kb
209Kb